-
GPU硬件加速计算通过深度优化OpenCL或Vulkan等GPU计算框架,充分挖掘Mali GPU的并行计算潜力,解决CPU算力瓶颈和GPU闲置问题。
-
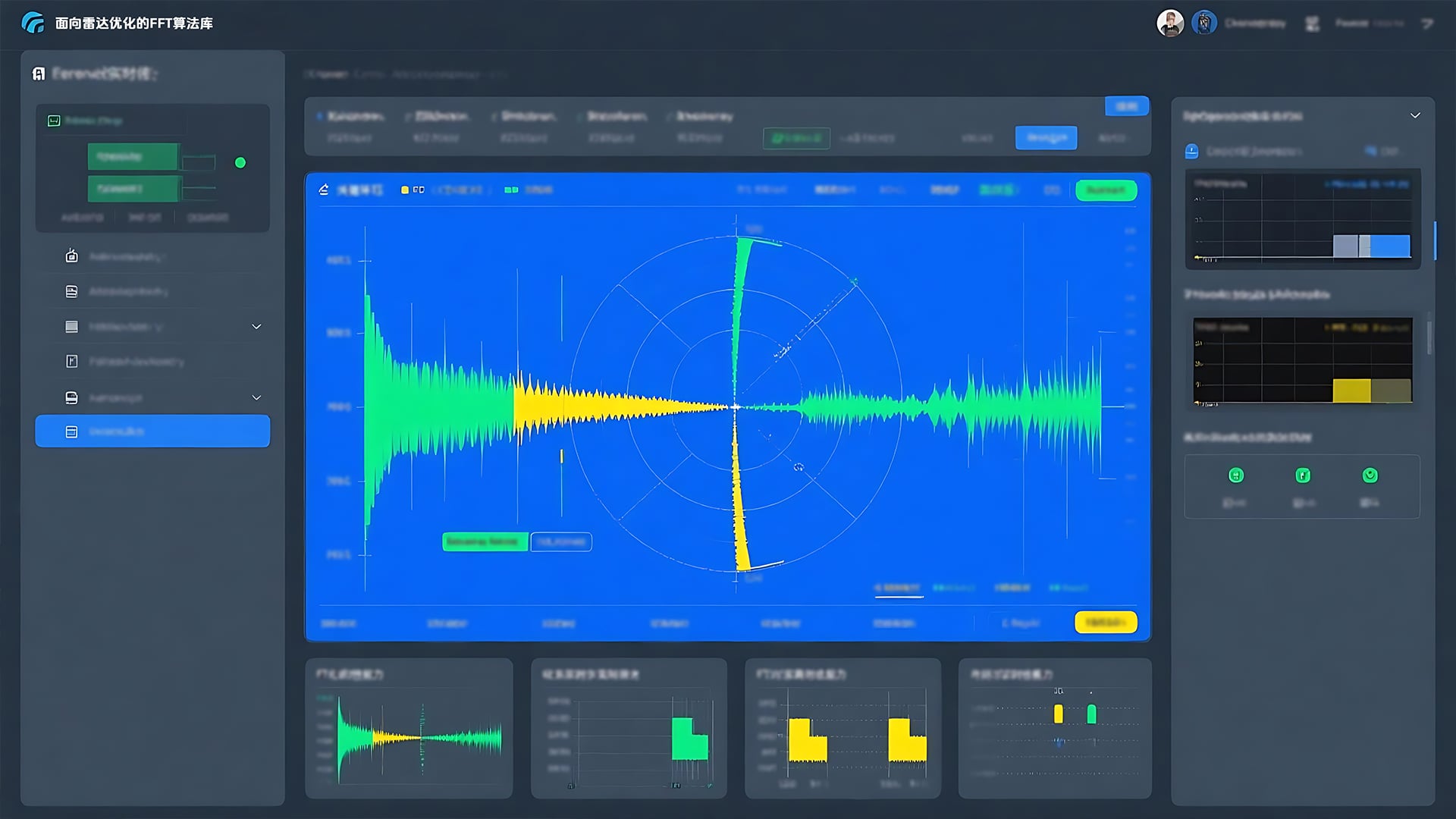
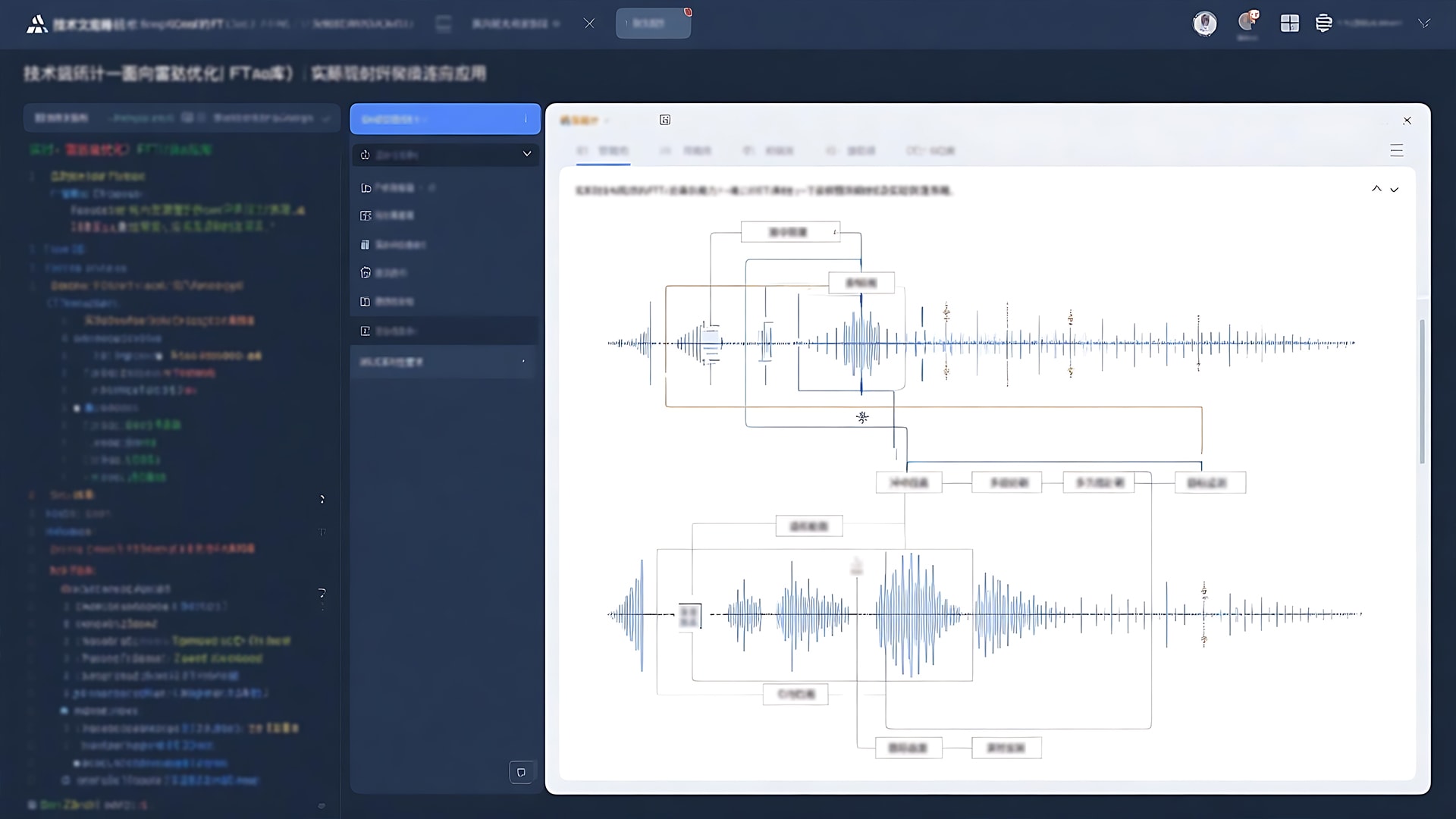
面向信号处理优化的FFT算法库在雷达信号处理链的关键环节(如脉冲压缩、多普勒处理、目标检测)提供实时、低延迟的FFT计算能力,满足严苛的嵌入式实时性要求。
-
标准化、易集成的API接口将底层复杂的GPU编程和优化细节封装起来,对外提供简洁、标准的C/C++ FFT函数接口, 大幅降低开发门槛。